DeepSeek令人惊讶的负担得起的AI模型挑战了行业巨头。虽然其DeepSeek V3型号仅具有600万美元的预培训成本,但仔细观察表明,投资更加巨大。
 图像:ensigame.com
图像:ensigame.com
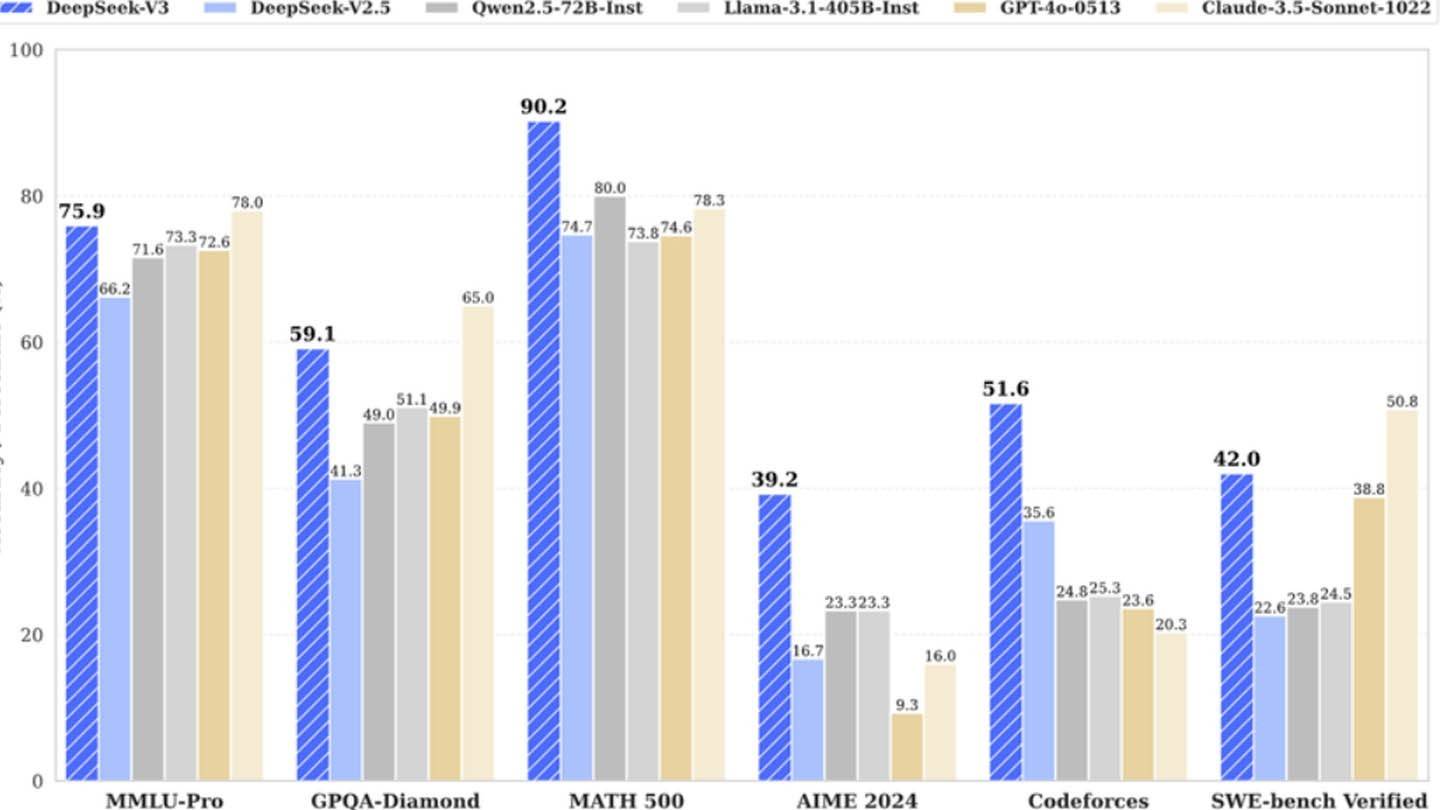
DeepSeek V3利用创新技术:多token预测(MTP),以提高准确性和效率; 专家(MOE)的混合物,利用256个神经网络(八个激活的令牌); 多头潜在注意(MLA),以改善信息提取。这些进步有助于其竞争性能。
 图像:ensigame.com
图像:ensigame.com
但是,半分析暴露了DeepSeek的使用约50,000个NVIDIA HOPPER GPU,这是一项巨大的投资,总计约16亿美元的服务器和9.44亿美元的运营成本。这与最初的600万美元索赔相矛盾,这仅反映了培训前的GPU支出。真正的成本包括研究,改进,数据处理和基础架构。
 图像:ensigame.com
图像:ensigame.com
DeepSeek作为高飞行对冲基金的子公司的独特结构允许敏捷性和快速创新。拥有其数据中心提供了对优化的完全控制。它对人才的大量投资,一些研究人员每年收入超过130万美元,这进一步强调了其承诺。
 图像:ensigame.com
图像:ensigame.com
尽管DeepSeek的“预算友好”叙述可以说是夸大的,但其成功却凸显了资金充足的独立AI公司的潜力。总投资超过5亿美元,再加上技术突破和强大的团队,是其成功的真正驱动力。与竞争对手的成本相比,例如Chatgpt4的1亿美元培训成本与DeepSeek的R1相比,这仍然是鲜明的。最终,DeepSeek的故事表明,尽管大量投资是至关重要的,有效的资源管理和创新仍然可以产生竞争成果。